“Hi,这是小5自学算力大集群相关知识的第12篇笔记。这一期我们会对Spark进行简单的了解。”
摘要
Spark本质上是对MapReduce的继承与发展。它在当今的数据中心计算中得到了广泛应用。
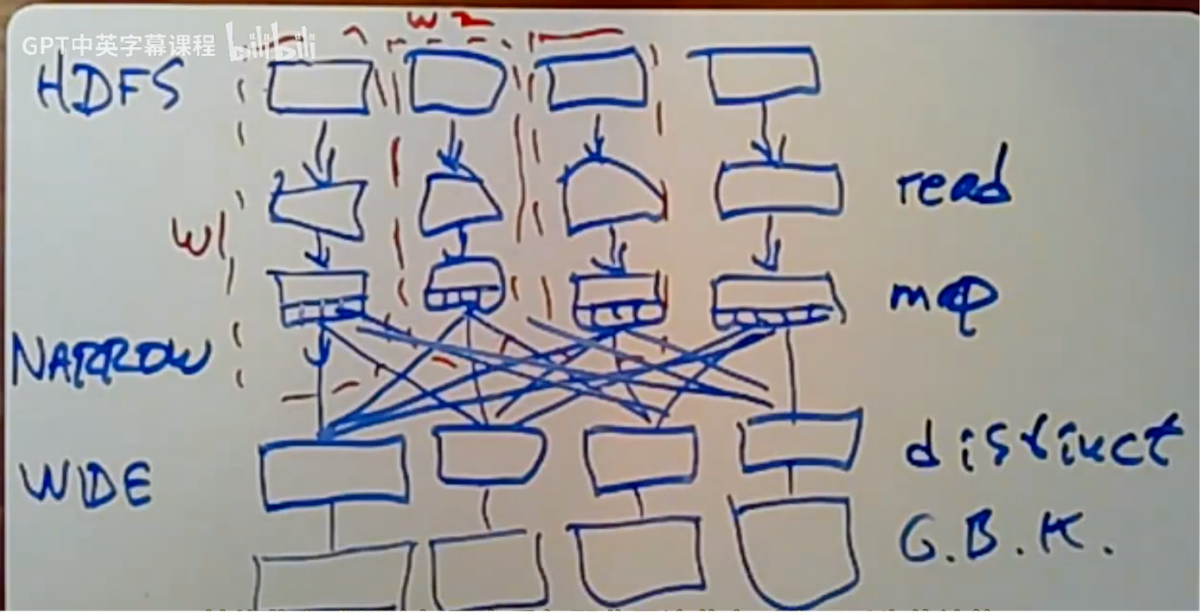
当Spark,读取文件时,它实际上是从类似GFS的分布式文件系统中读取文件(HDFS)。假设我们的一个文件,即输入文件,已经被分割成许多,比如64兆字节或任何可能的大小,在HDFS中。Spark知道当你开始调用collect来启动计算时,输入数据已经在HDFS中分区,并且它将尝试以相应的方式分配工作,让工作者进行相应的分工。对于输入文件而言,每个工作节点都会读取该输入文件的一部分。
Spark在开始任何数据处理之前,会创建完整的血统图。之后下一步是映射阶段,其中每个工作节点应执行一个小函数,该函数将输入的每一行分割成一个from-to-link 链接元组。这是一种纯粹的本地操作,因此可以在同一个工作节点上进行。Spark并非先读取整个输入分区,再对其执行映射操作,而是读取第一条记录,或者可能只是最初的几条记录,然后对每条记录进行映射处理。实际上,它会对每条记录尽可能多地应用转换操作,之后才继续从文件中读取下一部分内容。这样做的目的是为了避免存储整个输入文件,因为这些文件可能非常庞大。按记录逐条处理显然更力高效。这就是所说的“窄依赖”情况下的处理过程,即那些仅考虑每个数据记录独立处理,无需担心与其他记录关系的转换操作。
与MapReduce相比运行效率更高、更快。因为如果有多个相当于映射阶段的操作,它们在内存中只是简单地串联起来;而MapReduce,即使运行的是一些退化到仅包含映射阶段的MapReduce应用,每个阶段都会从GFS读取输入,进行计算,然后将输出写回GFS,紧接着下一阶段再进行读取、计算、写入。
- 关于广域变换(wide transformations)
Spark可能需要查看输入的所有分区,这和MapReduce中的 reduce 操作非常相似。通常情况下,执行映射(map)任务的工人(workers)也会执行区分(distinct)任务,但数据需要在两个变换之间移动,以将所有键汇聚在一起。
Spark会获取这个 map 的输出,通过键对每条记录进行哈希处理,并利用这个结果,取模(MOD,两个整数相除后的余数)于工作节点的数量。以确定哪些工作节点应该接收这些数据。
在最后一个窄阶段的最后一步,输出将被分割成对应于下个转换中不同工作者的桶,以便它们能够提取数据,并在此等待。每个工作节点都会运行尽可能多的阶段,直至完成所有狭窄阶段,并将输出分割存储到各个桶中。
当所有这些步骤完成后,便可以开始运行负责特定转换任务的工作进程,其第一步是前往其他每个工作进程,获取上一阶段筛选输出的相关存储桶。然后可以运行distinct操作,因为所有给定的键都在同一个工作节点上,它们可以各自开始生成输出。
- 关于容错性
Spark的目标是容忍常见错误,不必具备能够容忍任何可能错误的万无一失的能力。例如,Spark不会复制驱动机器。其是一个驱动程序,它在某种程度上控制着计算过程,并了解血统图谱,如果驱动程序崩溃,可能需要重新运行整个程序。另一个前提,Spark假设输入数据以容错方式在HDFS上进行了复制。
Spark的策略是,如果某个工作节点发生故障,只需重新计算该节点负责的任何内容,即在其他节点或其他机器上重复那些因该节点丢失而丢失的计算。之所以在某个工作节点失败时不必完全从头计算,一个方法是每个工作节点实际上负责输入数据的多个分区。因此,Spark可以将这些分区移交给剩余的工作节点,每个节点只需处理一个分区,便能通过在不同工作节点上并行运行各个分区,来并行地重新计算因失败节点而丢失的部分。如果其他所有方法都失败了,Spark就会回到起点,从原始输入重新计算在那个机器上运行的一切。
但在一个具有广泛依赖关系的血统图场景下,工人(worker)节点如果失效。通常情况下,Spark在执行过程中,它会执行每一个转换操作,并为下一个转换提供输出,但并不会保留原始输出。因此,当Spark在执行这些转换时,它会丢弃与先前转换相关的所有数据。然而,一旦涉及这种广域变换,我们便面临一个问题:它不仅需要来自同一分区、同一工作节点的输入,还必须依赖于其他所有分区的数据。这些工作者虽然仍然存活,但却可能已经舍弃了该转换的输出结果。即,重新计算所需从其他所有分区获取的输入已不复存在。Spark的策略是允许进行检查点操作,即定期对特定变换进行检查点设置。
Spark本身不擅长处理流数据。Spark确实假设所有输入数据已预先可用,但在许多情况下,人们所拥有的输入实际上是一个数据流,例如他们正在记录网站上所有用户的点击行为,并希望通过分析这些数据来理解用户行为。其所做的大量工作是将数据流图明确化,它以整个血统图的风格来思考计算过程,包括计算阶段的血统图以及数据在这些阶段之间的移动,并且它会对这个图进行优化,其故障恢复也很大程度上依赖于对血统图的思考。
以上内容来自对 MIT 《分布式系统 6.824》的学习笔记,在此特别声明。