“祝大家新年快乐。”
摘要
- 主存储
CloudStack 旨在与各种通用型和企业级存储系统配合使用。如果所选虚拟机管理程序支持,CloudStack 还可以利用虚拟机管理程序主机内的本地磁盘。客户机虚拟磁盘的存储类型支持因所选虚拟机管理程序而异。
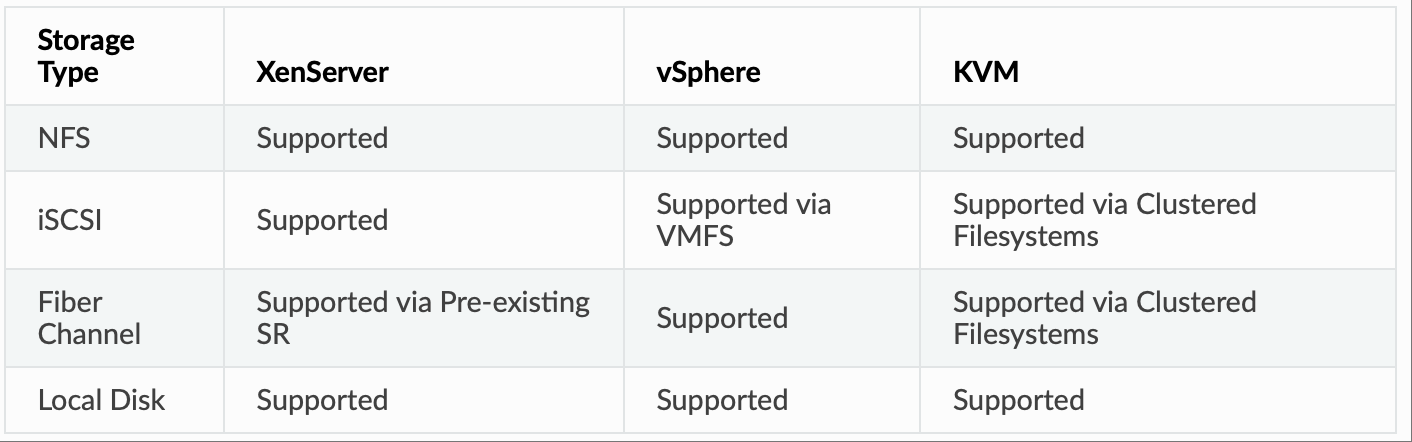
CloudStack 官方不支持将集群逻辑卷管理器 (CLVM) 用于 KVM。
- 二级存储
CloudStack 旨在与任何可扩展的二级存储系统配合使用。唯一的要求是二级存储系统支持 NFS 协议。对于大型多区域部署,CloudStack 也支持使用 S3 兼容的存储作为二级存储。这使得二级存储可以跨越整个区域,但由于大多数虚拟机管理程序无法直接挂载 S3 类型的存储,因此必须在每个区域中维护一个 NFS 暂存区。
- 配置
小规模部署
在小规模部署中,单个 NFS 服务器可以同时作为主存储和二级存储。该 NFS 服务器必须导出两个独立的共享,一个用于主存储,另一个用于二级存储。这可以是运行在 Linux 操作系统上的 NFS 服务的实例或物理主机,也可以是虚拟软件设备。在小规模部署中,磁盘和网络性能仍然至关重要,它决定了在部署、运行或创建实例快照时能否获得良好的体验。
大规模部署
在大规模环境中,主存储和二级存储通常由独立的物理存储阵列组成。
模板部署完成后,主存储很可能需要支持大部分随机读/写 I/O 操作。而二级存储则只会承受持续的顺序读或写操作。
在云环境中,大量用户会同时进行快照或部署实例,因此二级存储的性能对于保持良好的用户体验至关重要。
在设计存储方案时,首先要大致了解其需要支持的工作负载,这一点至关重要。除了要考虑数据量和存储接口的可用带宽(MB/s)之外,还应仔细考虑客户实例的 IOPS 需求。
- 存储架构
有很多不同类型的存储设备可供选择,它们通常都适用于 CloudStack 环境。在选择最适合您环境的存储设备时,应考虑具体的使用场景,而且预算限制往往使得“完美”的存储架构在经济上不切实际。
总体而言,现有主存储类型的架构可以分为 3 种类型:
1. 本地存储
本地存储最适合纯粹的“云时代”工作负载,这类工作负载很少需要在存储池之间迁移,而且不需要单个实例的高可用性。随着固态硬盘 (SSD) 的普及和价格下降,基于本地存储的实例现在可以提供以前只有拥有数十个磁盘的大型阵列才能实现的 IOPS 性能。本地存储具有高度可扩展性,因为增加主机数量时,存储容量也会相应增加。但本地存储的效率相对较低,因为它无法利用链接克隆或重复数据删除技术。
2. “传统”的基于节点的共享存储
传统的基于节点的存储阵列由一对控制器和若干磁盘组成,这些磁盘被放置在机架上。理想情况下,云架构应为每个 CloudStack Pod 配备一个这样的物理阵列,以将故障的影响范围限制在单个 Pod 内。虽然这在经济上通常不可行,但应尽可能地降低任何事件相对于单个阵列在任何区域的影响范围。使用共享存储可以在主机发生故障时立即在备用主机上重启工作负载。这些共享存储阵列通常能够创建“存储层”,例如使用大容量 SATA 磁盘、15k SAS 磁盘和 SSD。这些性能不同的存储层可以作为不同的产品提供给用户。阵列的容量规划应考虑工作负载所需的 IOPS 以及要存储的数据量。此外,还应考虑存储阵列预计支持的实例数量以及控制器所能提供的最大网络带宽。
3. 集群共享存储
集群式共享存储阵列是新一代存储技术,它没有单一的数据进出接口,而是将数据分布在所有活动节点上,从而显著提升了可扩展性和性能。某些共享存储阵列甚至能够在单个节点发生故障的情况下,确保所有数据仍然可用。
使用集群共享存储时,应仔细考虑网络拓扑结构,以避免在网络结构中造成瓶颈。
存储网络配置
在设计云时,不仅要考虑磁盘阵列的性能,还要考虑在交换结构和阵列接口之间传输流量的可用带宽。
- CloudStack 存储网络
首先需要了解的是主存储的配置过程。为任何给定集群创建主存储池时,CloudStack 管理服务器会指示每个主机的虚拟机管理程序挂载 NFS 共享或 iSCSI LUN。存储池在虚拟机管理程序中将以数据存储(VMware)、存储库(XenServer/XCP)或挂载点(KVM)的形式呈现。关键在于,是虚拟机管理程序本身与主存储通信,CloudStack 管理服务器仅与主机虚拟机管理程序通信。所有虚拟机管理程序都通过某种管理接口与外部通信——例如 ESXi 上的 VMkernel 端口或 XenServer 上的“管理接口”。由于 CloudStack 管理服务器需要与主机上的虚拟机管理程序通信,因此该管理接口必须位于 CloudStack 的“管理”网络或“私有”网络上。您的主机上可能配置了其他接口,用于承载主机内实例与客户机和公共流量之间的通信,但虚拟机管理程序本身无法通过这些接口进行通信。
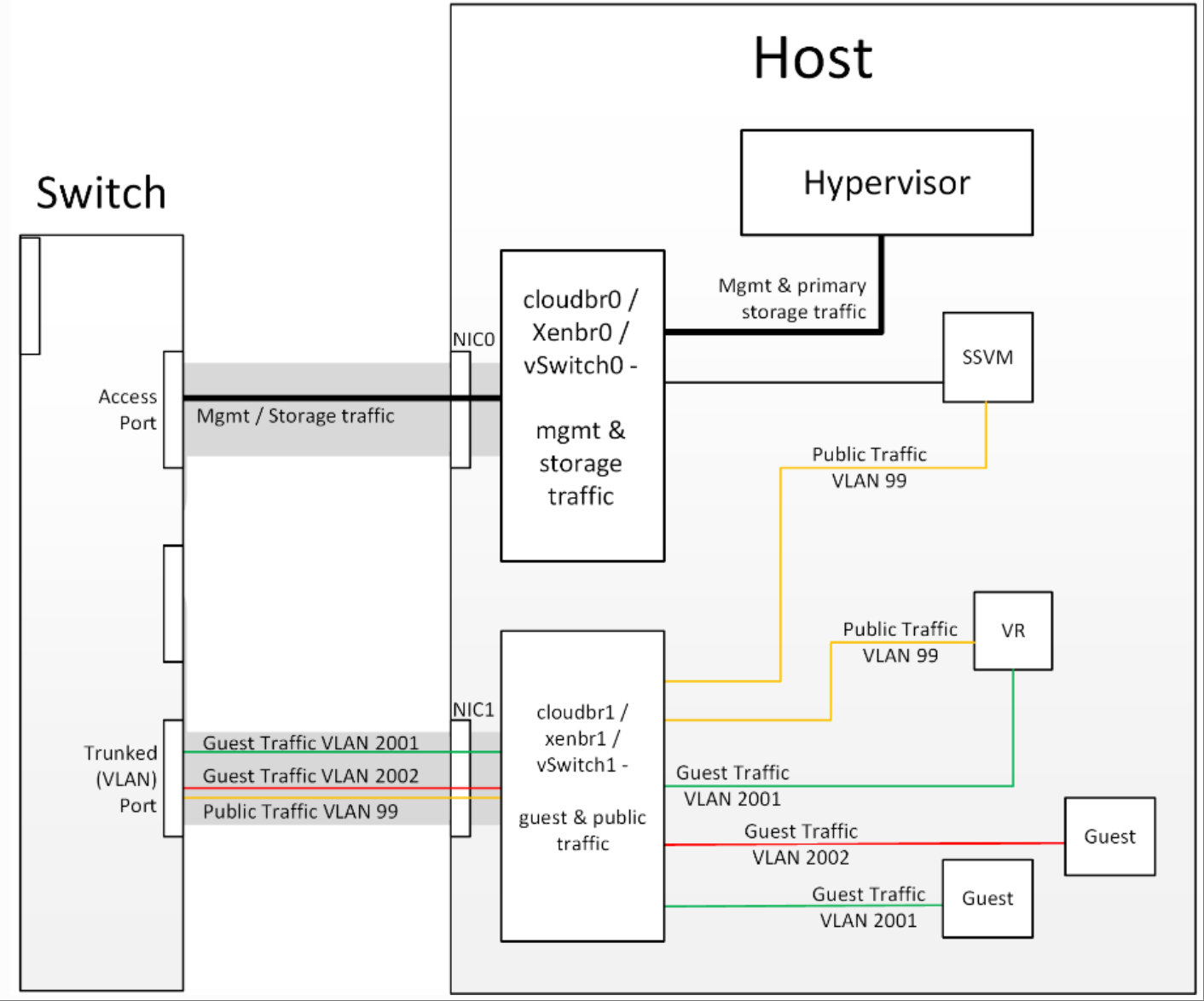
虚拟机管理程序通信
分离主存储流量对于纯粹的虚拟化背景用户来说,为存储流量创建专用接口的概念并不陌生;长期以来,iSCSI 流量使用专用交换结构以避免任何延迟或争用问题一直是最佳实践。在云(堆栈)环境中,我们有时会忘记,我们只是在编排虚拟机管理程序已经执行的流程,并且许多“常规”的虚拟机管理程序配置仍然适用。以下是解释这种流量分离工作原理的逻辑:
1. 如果您想要一个额外的接口供虚拟机管理程序通信(不包括绑定或捆绑的接口),则需要为其分配一个 IP 地址。
2. 创建虚拟机管理程序可使用的额外接口的机制是创建额外的管理接口。
3. 为了使虚拟机管理程序能够区分不同的管理接口,它们必须位于不同的(不重叠的)子网中。
4. 为了使“主存储”管理接口能够与主存储通信,主存储阵列上的接口必须与“主存储”管理接口位于同一个 CIDR 中。
5. 因此,主存储必须位于与管理网络不同的子网中。
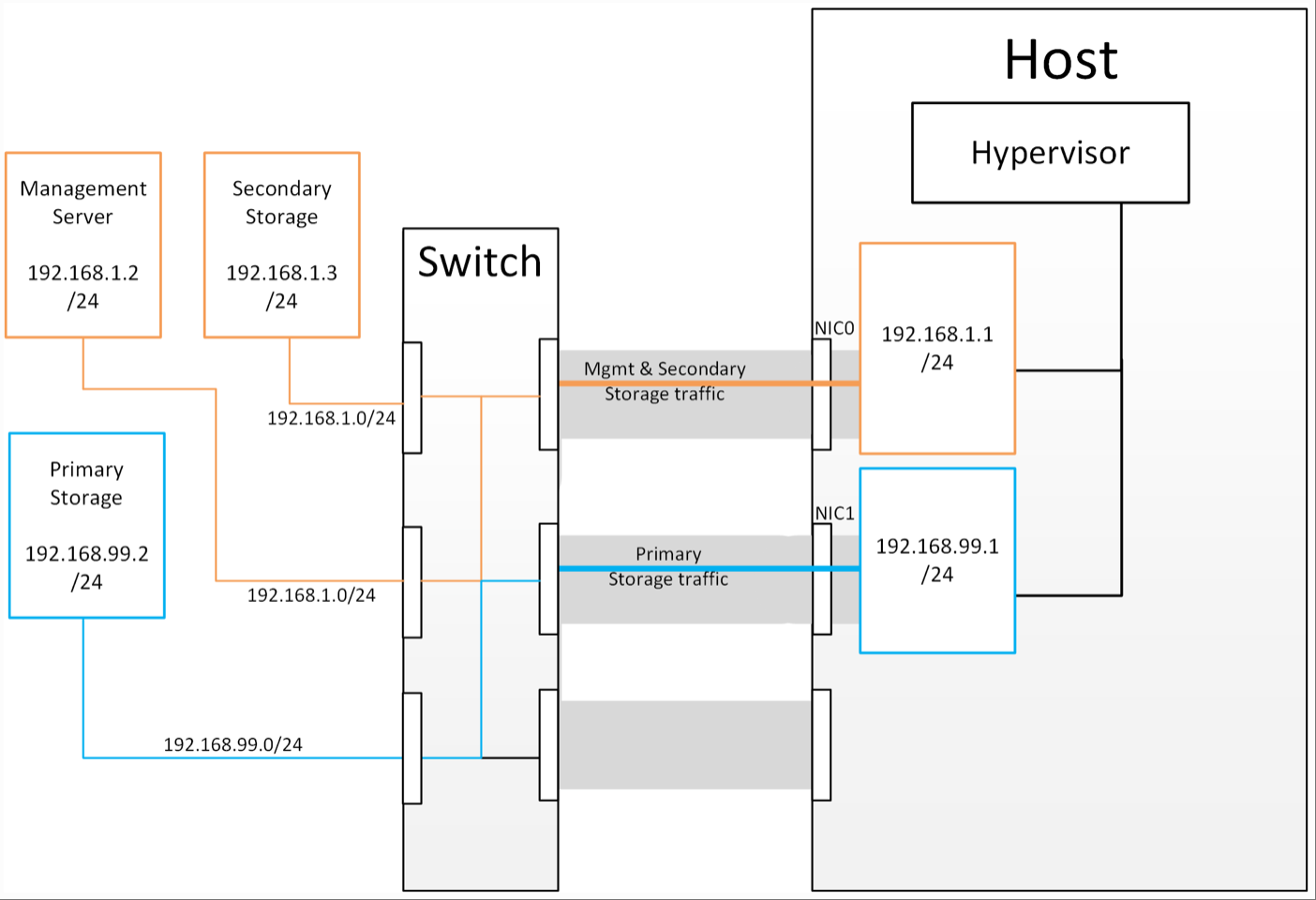
存储流量子网划分
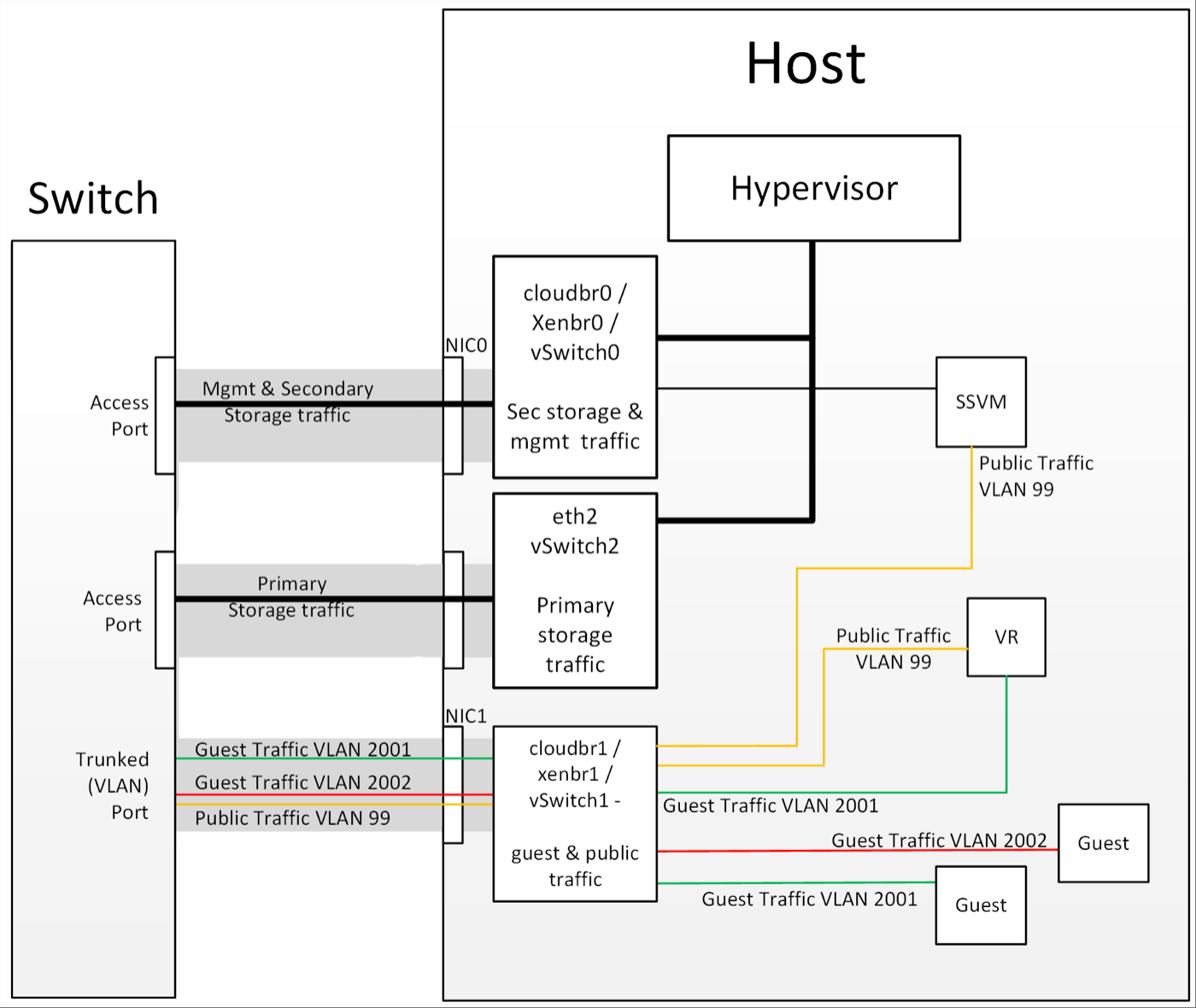
虚拟机管理程序与分离存储流量的通信
其他主存储类型如果您使用 PreSetup 或 SharedMountPoints 连接到基于 IP 的存储,则同样的原则也适用;如果主存储和“主存储接口”与“管理子网”位于不同的子网中,则虚拟机管理程序将使用“主存储接口”与主存储通信。
以上内容主要来自对 docs.cloudstack.apache.org 的学习,在此特别声明。